Introduction
本文介绍了编写的nVIDIA Cuda代码是如何编译成二进制的。
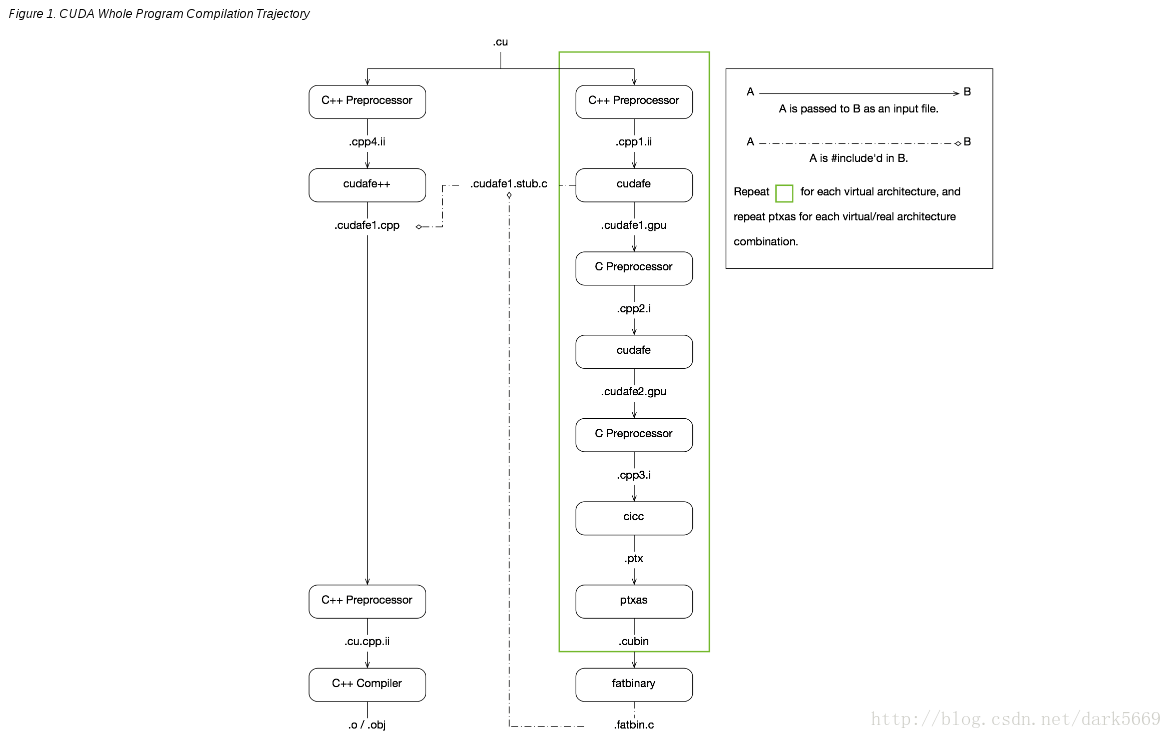
上图即为官方的流程图。
打印步骤
nvcc -O2 -c vectorAdd.cu -keep -arch sm_20 --dryrun
以samples/0_Simple/vectorAdd为例,写上述编译命令。由于vectoradd这个样例比较简单,因此可以直接使用命令进行编译。
参数说明:
| 参数 | 含义 |
|---|---|
| O2 | 该优化选项会牺牲部分编译速度,除了执行-O1所执行的所有优化之外,还会采用几乎所有的目标配置支持的优化算法,用以提高目标代码的运行速度。 |
| c | --compile 源代码文件 |
| arch | --gpu-architecture 要编译成哪个计算能力型号的程序,比如compute_50 , sm_50 |
| keep | 保留编译过程中所有的中间文件 |
| dryrun | "干运行",只列出编译命令来,不执行他们 |
编译过程
# 读取环境变量
_SPACE_=
_CUDART_=cudart
_HERE_=/usr/lib/nvidia-cuda-toolkit/bin
_THERE_=/usr/lib/nvidia-cuda-toolkit/bin
_TARGET_SIZE_=
_TARGET_DIR_=
_TARGET_SIZE_=64
NVVMIR_LIBRARY_DIR=/usr/lib/nvidia-cuda-toolkit/libdevice
PATH=/usr/lib/nvidia-cuda-toolkit/bin:/opt/jdk/bin:/opt/jdk/jre/bin:/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games:/opt/android_sdk/platform-tools:/usr/local/cuda-7.0/bin:/opt/android_sdk/ndk-bundle:/home/find/d/fpga/DocNav/:/usr/local/cuda/nvvm/bin
LIBRARIES= -L/usr/lib/x86_64-linux-gnu/stubs
# 使用c++ 预处理器进行预处理,生成中间文件 .cpp1.ii
#将一些定义好的枚举变量(例如cudaError)、struct(例如cuda的数据类型float4)、静态内联函数、extern “c++”和extern的函数、
#还重新定义了std命名空间、函数模板等内容写在main函数之前。
gcc -D__CUDA_ARCH__=200 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ -O2 -D"__CUDACC_VER__=80044" -D"__CUDACC_VER_BUILD__=44" -D"__CUDACC_VER_MINOR__=0" -D"__CUDACC_VER_MAJOR__=8" -include "cuda_runtime.h" -m64 "vectorAdd.cu" > "vectorAdd.cpp1.ii"
# 调用cudafe将分别执行在 host 和 device 上code 分离,生成.cudafe1.gpu
cudafe --allow_managed --m64 --gnu_version=40804 -tused --no_remove_unneeded_entities --gen_c_file_name "vectorAdd.cudafe1.c" --stub_file_name "vectorAdd.cudafe1.stub.c" --gen_device_file_name "vectorAdd.cudafe1.gpu" --nv_arch "compute_20" --gen_module_id_file --module_id_file_name "vectorAdd.module_id" --include_file_name "vectorAdd.fatbin.c" "vectorAdd.cpp1.ii"
# 使用c 预处理器进行预处理,生成中间文件 .cpp2.i
gcc -E -x c++ -D__CUDACC__ -D__NVCC__ -O2 -D"__CUDACC_VER__=80044" -D"__CUDACC_VER_BUILD__=44" -D"__CUDACC_VER_MINOR__=0" -D"__CUDACC_VER_MAJOR__=8" -include "cuda_runtime.h" -m64 "vectorAdd.cu" > "vectorAdd.cpp4.ii"
# 继续使用cudafe进行分离?
cudafe++ --allow_managed --m64 --gnu_version=40804 --parse_templates --gen_c_file_name "vectorAdd.cudafe1.cpp" --stub_file_name "vectorAdd.cudafe1.stub.c" --module_id_file_name "vectorAdd.module_id" "vectorAdd.cpp4.ii"
# 预处理,因为不同架构gpu的计算能力不同,那么需要进行相应的处理
gcc -D__CUDA_ARCH__=200 -E -x c -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -D__NVCC__ -D__CUDANVVM__ -O2 -D__CUDA_FTZ=0 -D__CUDA_PREC_DIV=1 -D__CUDA_PREC_SQRT=1 -m64 "vectorAdd.cudafe1.gpu" > "vectorAdd.cpp2.i"
cudafe -w --allow_managed --m64 --gnu_version=40804 --c --gen_c_file_name "vectorAdd.cudafe2.c" --stub_file_name "vectorAdd.cudafe2.stub.c" --gen_device_file_name "vectorAdd.cudafe2.gpu" --nv_arch "compute_20" --module_id_file_name "vectorAdd.module_id" --include_file_name "vectorAdd.fatbin.c" "vectorAdd.cpp2.i"
gcc -D__CUDA_ARCH__=200 -E -x c -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDABE__ -D__CUDANVVM__ -D__USE_FAST_MATH__=0 -O2 -D__CUDA_FTZ=0 -D__CUDA_PREC_DIV=1 -D__CUDA_PREC_SQRT=1 -m64 "vectorAdd.cudafe2.gpu" > "vectorAdd.cpp3.i"
# 生成ptx文件
cicc -arch compute_20 -m64 -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 -nvvmir-library "/usr/lib/nvidia-cuda-toolkit/libdevice/libdevice.compute_20.10.bc" --orig_src_file_name "vectorAdd.cu" "vectorAdd.cpp3.i" -o "vectorAdd.ptx"
# PTX离线编译,将代码编译成一个确定的计算能力和SM版本,对应的版本信息保存在cubin中。
ptxas -arch=sm_20 -m64 "vectorAdd.ptx" -o "vectorAdd.sm_20.cubin"
fatbinary --create="vectorAdd.fatbin" -64 --cmdline="" "--image=profile=sm_20,file=vectorAdd.sm_20.cubin" "--image=profile=compute_20,file=vectorAdd.ptx" --embedded-fatbin="vectorAdd.fatbin.c" --cuda
gcc -D__CUDA_ARCH__=200 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__USE_FAST_MATH__=0 -O2 -D__CUDA_FTZ=0 -D__CUDA_PREC_DIV=1 -D__CUDA_PREC_SQRT=1 -m64 "vectorAdd.cudafe1.cpp" > "vectorAdd.cu.cpp.ii"
# 用gcc链接所有的.o 文件
gcc -c -x c++ -O2 -fpreprocessed -m64 -o "vectorAdd.o" "vectorAdd.cu.cpp.ii"
对于makefile复杂的项目
上面的例子是直接nvcc编译就可以的,但是绝大多数项目都不是这么简单。下文以cuda sample的matrixMul矩阵乘法为例。
其makefile中可以看出,项目根据平台的不同,生成了不同的中间文件,最后尽管只有一个可执行文件。
# Gencode arguments
ifeq ($(TARGET_ARCH),armv7l)
SMS ?= 20 30 32 35 37 50 52
else
SMS ?= 20 30 35 37 50 52
endif
可以只留下你自己的版本。这里的数字后面说区别。
然后在ALL_CCFLAGS :=区块,自己添加一个-keep即可,不清楚为什么加上dryrun会出错
ALL_CCFLAGS += -keep
但是由于matrixMul项目用到了一个头文件#include <helper_functions.h>,在使用keep参数make时,会提示错误。这个头文件主要提供了从命令行获取参数的功能,比如checkCmdLineFlag函数,简单修改下代码即可。
贴出我改好的代码:
Comments